Over the recent weekend I read Ellyssa Kroski’s superbly researched and written new article, The Hype and Hullabaloo of Web 2.0. It’s a must-read piece whether you’re a die-hard aficionado or a battle-hardened detractor. The article is essentially an in-depth snapshot of the current state of affairs of our favorite topic. And it’s particularly well-cited with supporting material that also makes excellent reading. I definitely encourage you to give it a close read.
One of the things Ellyssa discusses is some practical examples of harnessing collective intelligence, one of the linchpin techniques of successful Web 2.0 software. The article describes this as when the “critical mass of participation is reached within a site or system, allowing the participants to act as a filter for what is valuable.” I single this definition out as an understatement. While the article gives some excellent examples of collective intelligence and I’m not certainly faulting Ellyssa in the slightest, I’m just saying that observing that harnessing collective intelligence allows Web systems to be “better” is like saying Moore’s Law states how computers get faster over time. It wasn’t for nothing that Einstein said that compound interest was the most powerful force in the universe. And harnessing collective intelligence is about those very same exponential effects.
But speaking in generalities invariably ends up derailing all too many discussions of Web 2.0 ideas. So along this line, I thought I’d dive in and provide a list of concrete ways that Web software can leverage collective intelligence to particular effect. If you’re not sure about this, don’t forget, the entire product that highly successful companies like eBay have to offer is the aggregation of their user contributions. So too is the blogosphere. The concepts here are potent and immensely powerful. Thus, mastery of architectures of participation to create real value will be essential to success in the Web of the future.
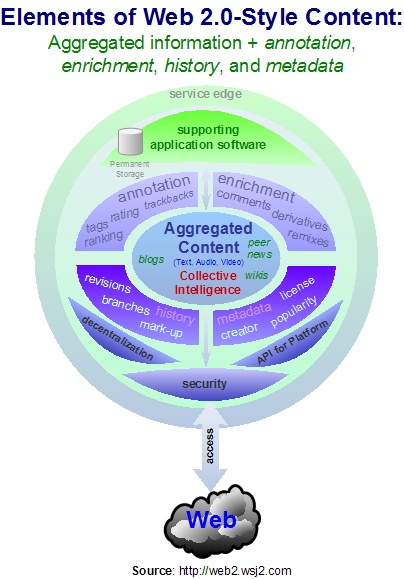
Five Great Ways to Harness Collective Intelligence
1) Be The Hub of A Hard To Recreate Data Source – This is a classic Web 2.0 concept and success here often devolves to being the first entry with an above average implementation. Examples include Wikipedia, eBay, and others which are almost entirely the sum of the content their users contribute. And far from being a market short on remaining space, it’s lack of imagination that’s often the limiting factor for new players. There is so much more terrific software like digg and del.icio.us waiting to be created. So don’t wait until it’s perfect, get your collective intelligence technique out there that creates a user base virtually on its own from the innate usefulness of its data. Just be careful and avoid crowded niches, like peer production news.
2) Seek Collective Intelligence Out – This is the Google approach. There is an endless supply of existing information waiting out there on the Web to be analyzed, derived, and leveraged. In other words, you can be smart and use what already exists instead of waiting for it to be contributed. For example, Google uses hyperlink analysis to determine the relevance of a given page and builds its own database of content which it then shares through its search engine. Not only does this approach completely avoid a dependency on the ongoing kindness of strangers it also lets you build a very big content base from the outset. This ultimately has interesting intellectual property implications, as I’ve discussed before.
3) Trigger Large-Scale Network Effects – This is what Katrinalist and CivicSpace did and many others have done. This is arguably harder to do than either of the methods above but it can be great in the right circumstance. With one billion connected users on the Web, the potential network effects are theoretically almost limitless. Smaller examples can be found in things like the Million Dollar Pixel Page. That’s not to say that network effects don’t cut both ways and are probably not very repeatable, but when they happen, they can happen big.
4) Provide A Folksonomy – Self-organization by your users can be a potent force to allow the content on your site or social software to be used in a way that more befits your community. It’s the law of unintended uses again, something Web 2.0 design patterns strongly encourage. Allow users to tag the data they contribute or find and then make those tags available to others so they can discover and access things in dynamically evolving categorization schemes. Use real-time feedback to display tag clouds of the most popular tags and data; you’ll be amazed at how much better your software works. It worked for Flickr and del.icio.us and it’ll probably work for you too.
5) Create a Reverse Intelligence Filter – Like Ellyssa points out, the blogosphere is the greatest example of this and sites like Memeorandum have been using this to great effect. The idea is that hyperlinks, trackbacks, and other information references can be counted and used as a reference to determine what it’s important. Combined with temporal filters and other techniques and you can create situation awareness engines easily. It sounds similar to #2 but it’s different in that it can be used with or without external data sources and is aimed not at finding but at eliding the irrelevant altogether as an active filter.
Of course, there are other important ways that collective intelligence can be exploited but these are some of the main ones. I’ll continue to talk about this in future posts since effectively harnessing collective intelligence is one of the first order ideas in the Web 2.0 practice set.
What other techniques for leveraging collective intelligence are there?
